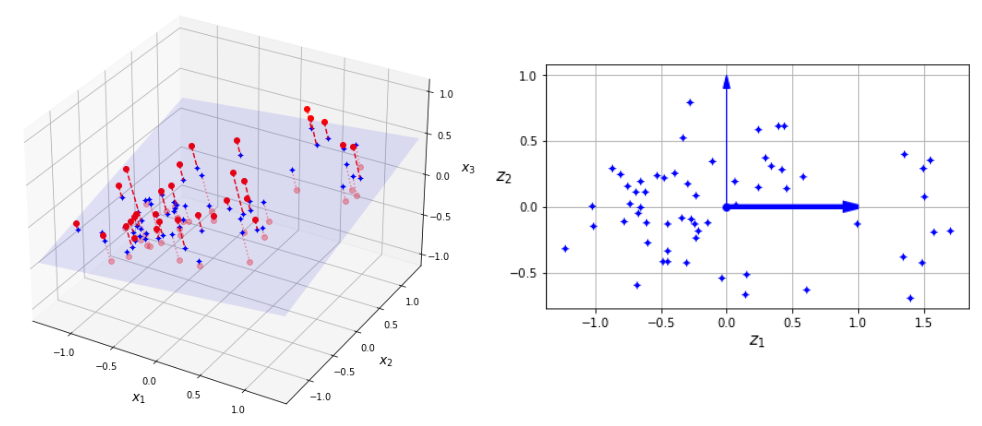
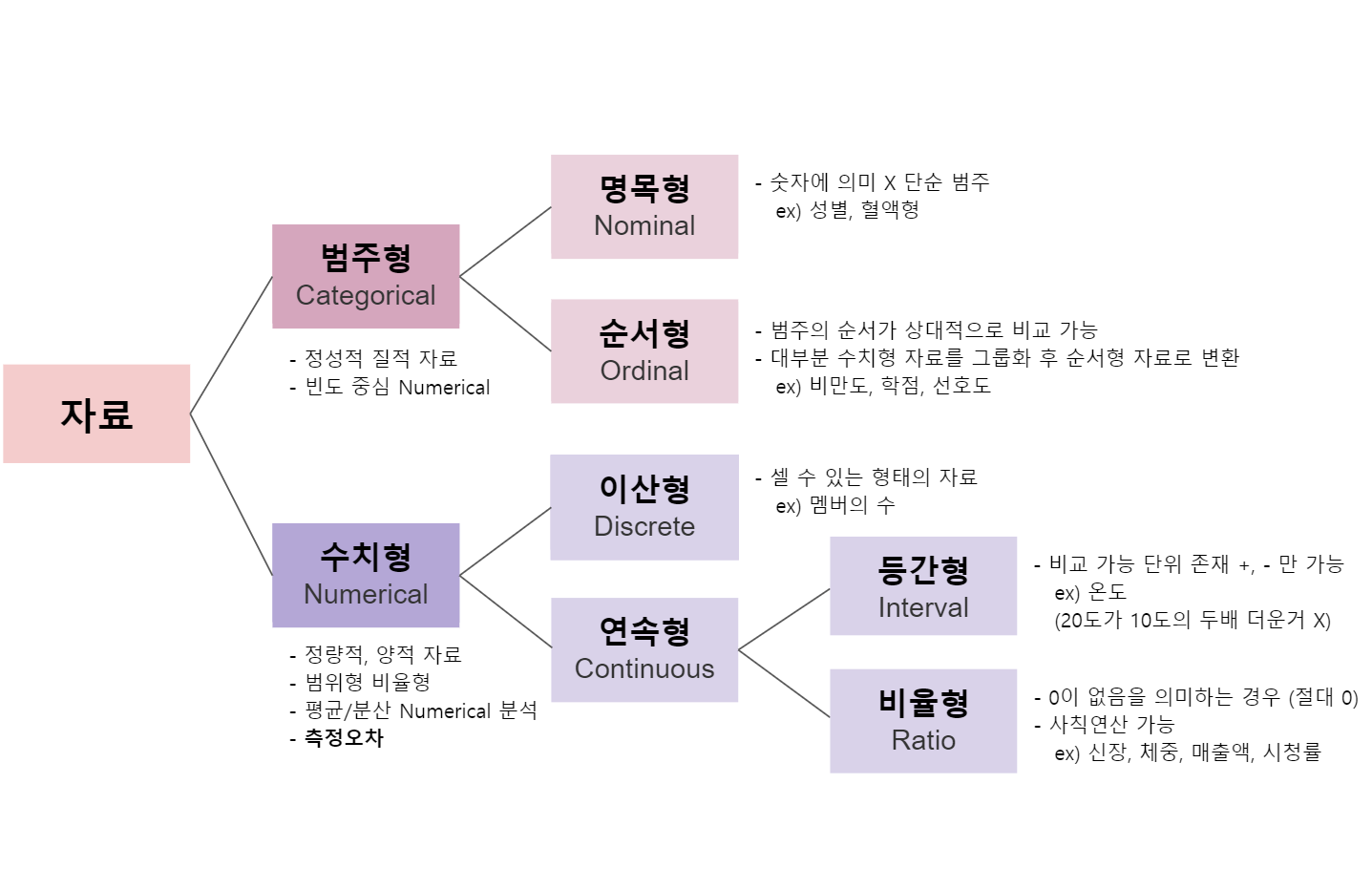
Dimension Reduction(차원 축소) * 차원(dimensionality) = 독립변수(입력변수)의 수 불필요한 변수의 사용 시 1. 모델의 과적합(overfitting) 현상 2. 계산 비용 증가 3. 시각화의 어려움 머신러닝에서 정확도 감소를 최소화하면서 차원 축소하는 것이 중요 Curse of Dimensionality (차원의 저주) 차원이 커질수록 해당 공간(space)을 표현하데 필요한 데이터가 기하급수적으로 많아지는 현상 > cost 증가 차원 증가 > 데이터 밀집도 감소 > 데이터 포인트 간의 거리 멀어짐 > 패턴 발견 어려움 > 모델 정확도 감소 Feature Selection vs Feature Extraction - 장단점 Feature Selection(변수 선택) 장점 ..