이번에 소개할 논문은 제가 저번 여름에 Kaggle Competition 기흉 segmentation을 할 때 주로 사용했던 모델인 Deeplabv3+입니다.
Deeplab은 Deeplabv1에서 출발해서 Deeplabv2, Deeplabv3을 거쳐서 Deeplabv3+까지 여러 버전이 있습니다.
버전이 올라가면서 여러가지 특징들이 더해지게 되는데요!
먼저, 커다란 특징들 부터 소개해 드리겠습니다.
모델 특징
- Encoder-decoder 구조

많은 모델에 사용되는 Encoder-decoder 구조가 deeplabv3+에서도 사용됩니다.
가장 유명한 U-net의 Encoder-decoder구조 사진을 가져와봤는데요.
빨간 선을 기준으로 왼쪽이 encoder 오른쪽이 decoder로 encoder에서는 input이미지를 다운 샘플링해 특징을 추출해 내는 역할을 하고, decoder는 업 샘플링을 하며 segmentaion map을 만들어 냅니다.
또 인코더로 부터 다운 샘플링된 피쳐 맵의 복사본을 디코더가 받아 활용해 정보 손실을 줄이는 방법도 많이 사용됩니다.

Deeplabv3+의 구조를 보면 파란 박스 부분이 인코더, 빨간 박스 부분이 디코더로
(U-net그림과 다르게 누워있는 모양)
U-net과 마찬가지로 인코더는 인풋 이미지를 다운 샘플링해 디코더 부분에 전달해 주는 것을 볼 수 있습니다.
- Atrous Convolution

Atrous convoltion이란 기존 convoltion 과는 조금 다르게 필터 사이에 간격을 두는 것입니다.
그림을 보면 이해가 바로 되실 것 같은데요.
rate라는 값에 따라 그 간격이 결정되고 일반 convolution 필터처럼 간격이 없는 것은 rate = 1에 해당됩니다.
atrous convolution의 장점은 파라미터의 수를 늘리지 않고도 receptive field를 넓일 수 있다는 것입니다.
즉 한 픽셀이 볼 수 있는 영역이 커집니다. (컨볼루션 한 번이 한 픽셀을 만들기 때문)

위 그림을 보면 파랑 화살표는 일반 컨볼루션 사용한 피쳐맵이고 빨간 화살표는 atrous convolution을 사용한 피쳐 맵인데
해상도 측면에서 확실히 차이가 나는 것을 볼 수 있다.
- Depthwise Separable Convolution

Depthwise seperable convolution이란 한 레이어의 input 채널을 따로 따로 convolution 하고
concatenate 한 후 채널 수를 조정하는 방식입니다.
세부적인 설명을 더 해보자면 Depthwise seperable convolution은
크게 Depthwise Convolution과 Pointwise Convolution 부분으로 나눌 수 있는데요.
Deptwise Convolution은 한 layer의 input channel을 따로따로 convolution 하고 concatenate 하는 것을 말합니다.
Pointwise Convolution은 1x1 convolution을 통해 output channel 수를 조정하는 것을 말합니다.
이 둘을 진행하고 나면 커널의 크기를 KxK, Output channel 수를 M이라고 할 때, 기존 파라미터수가 KxKxM일 때 Depthwise seperable Convolution은 KxK+M이 되므로 파라미터수를 줄일 수 있습니다. (연산량 또한 줄어듭니다.)
이렇게 파라미터 수와 연산량이 줄어듬에도 불구하고 기존 convolution과 성능이 비슷하다고 합니다.
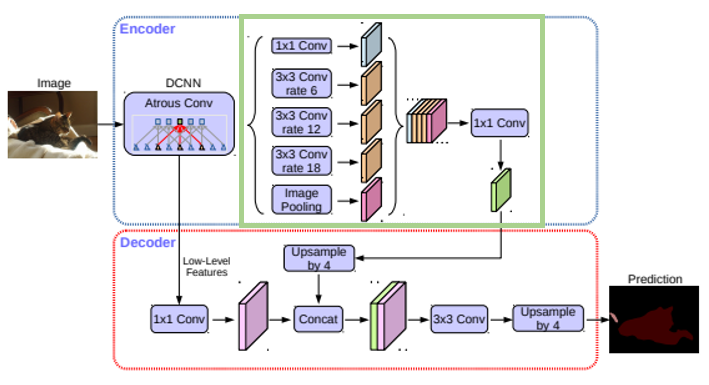
- Atrous Spatial Pyramid Pooling (ASPP)

ASSPP는 특정 layer에 대해서 다양한 rate의 Atrous Convolution을 적용해 결과를 concat하고 1x1 Convolution 한 방법입니다.
ASSPP를 사용하면 Atrous Convolution rate에 따른 다양한 크기의 물체를 잘 인식해 결과를 내게 되는 장점이 있습다.
실제 Deeplab v1에서는 크기가 다른 물체들이 있을 때 이를 잘 segmentation하지 못하는 문제점이 있었고
이 문제를 해결하고자 v2로 넘어갈 때 ASPP를 활용하기도 했습니다.
- Residual learning

마지막으로 많은 모델에서 활용되고 있는 residual learning입니다.
Input 값을 Output값에 더해주어 망이 깊어짐에 따라 나타나는 vanishing/ exploding gradient 문제를 줄여준다는 장점이 있습니다.
----------------------------------------------------------------------------------------------------------------------------
여기까지 커다란 특징에 대해서 설명을 마쳤습니다.
이번에는 모델 전체적인 구조를 따라가면서 어디서 그 특징들이 활용되었는지 알아보겠습니다.
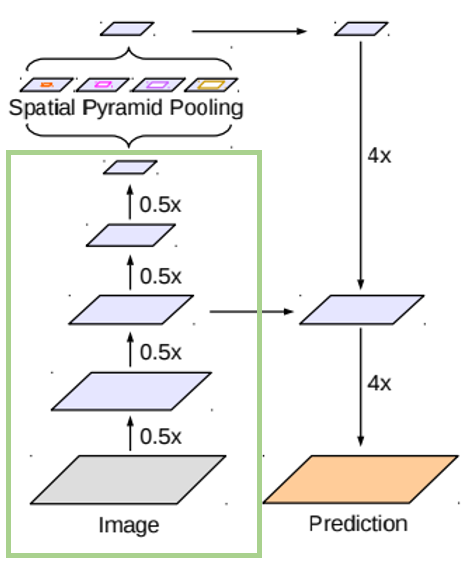
오른쪽 그림은 모델의 전체적인 구조를 보여주는 그림입니다.
인코더 부분과 디코더 부분으로 나뉘는 것을 보실 수 있습니다.
인코더 부분 중에 연두 박스에 해당되는 부분이 오른쪽 layer들입니다.
(오른쪽 그림을 보시면 위에 설명드렸던 residual learning 도 보실 수 있습니다.)
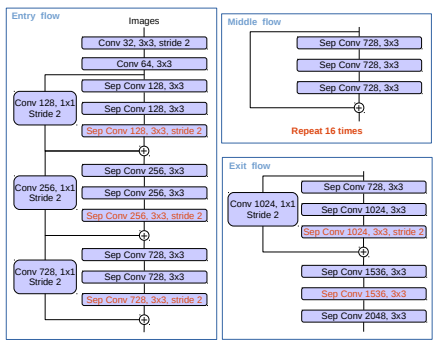
오른쪽 사진은 기존의 Xeception을 수정한 구조인데요.
더 많은 레이어 추가, max pooling을 depthwise separable convolution with stride로 대체,
batch normalization과 ReLU 추가되었다고 합니다.
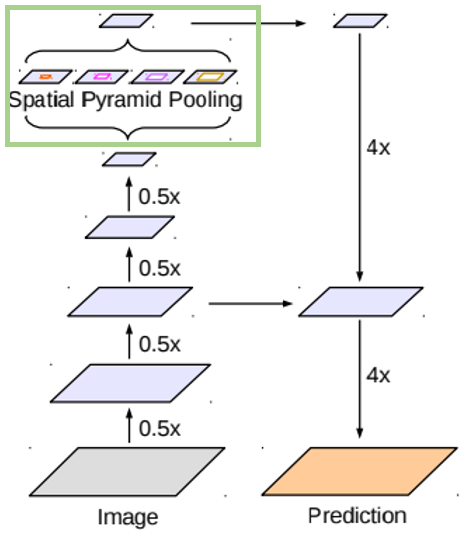
여러 레이어들을 거친 후 ASSPP를 적용합니다.
두 사진 모두 deeplabv3+의 전체적인 구조를 보여주는 사진입니다.
(연두 박스 부분이 ASSPP)
제가 이 부분 때문에 혼란이 왔었는데요..
잠깐 말씀드리면 왼쪽 인코더에서 디코더로 전달되는 피쳐 맵이 오른쪽 그림에서 연두색 피쳐맵이 아니라는 점,,
디코더 쪽에 작은 글씨로 Low Level Features라고 되어있는 부분이 전달되는 피쳐 맵입니다.
(너무 당연한 것일 수도 있지만 저는 헷갈렸습니다 ㅜㅜ)
ASSPP까지 적용했으면 디코더 부분에서 upsampling을 진행해 최종 output을 내게 됩니다.
이 논문에서는 PASCAL VOC 2012 dataset과 Cityscapes dataset을 이용했고
각각 performance가 89.0%, 82.1% 정도 된다고 합니다.

여기까지 deeplabv3+ 설명 마무리하겠습니다.
부족한 부분이 있다면 댓글로 알려주시면 감사하겠습니다!
참고 논문 - Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
'논문 정리' 카테고리의 다른 글
| [CAM] Learning Deep Features for Discriminative Localization (1) | 2020.01.25 |
|---|---|
| [ GAN ]쉽게 이해하는 GAN(Generative Adversarial Network) (1) (0) | 2020.01.09 |